
# JS 进阶知识点
# 手写 call、apply 及 bind 函数
首先从以下几点来考虑如何实现这几个函数:
- 不传入第一个参数,那么上下文默认为 window
- 改变了 this 指向,让新的对象可以执行该函数,并能接受参数
那么我们先来实现 call:
Function.prototype.myCall = function(context) {
if (typeof this !== 'function') {
throw new TypeError('Error')
}
context = context || window
context.fn = this
const args = [...arguments].slice(1)
const result = context.fn(...args)
delete context.fn
return result
}
2
3
4
5
6
7
8
9
10
11
以下是对实现的分析:
- 首先 context 为可选参数,如果不传的话默认上下文为 window
- 接下来给 context 创建一个 fn 属性,并将值设置为需要调用的函数
- 因为 call 可以传入多个参数作为调用函数的参数,所以需要将参数剥离出来
- 然后调用函数并将对象上的函数删除
以上就是实现 call 的思路,apply 的实现也类似,区别在于对参数的处理:
Function.prototype.myApply = function(context) {
if (typeof this !== 'function') {
throw new TypeError('Error')
}
context = context || window
context.fn = this
let result
// 处理参数和 call 有区别
if (arguments[1]) {
result = context.fn(...arguments[1])
} else {
result = context.fn()
}
delete context.fn
return result
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
bind 的实现对比其他两个函数略微地复杂了一点,因为 bind 需要返回一个函数,需要判断一些边界问题,以下是 bind 的实现:
Function.prototype.myBind = function (context) {
if (typeof this !== 'function') {
throw new TypeError('Error')
}
const _this = this
const args = [...arguments].slice(1)
// 返回一个函数
return function F() {
// 因为返回了一个函数,我们可以 new F(),所以需要判断
if (this instanceof F) {
return new _this(...args, ...arguments)
}
return _this.apply(context, args.concat(...arguments))
}
}
// 测试代码
function fn(a) {
console.log(this); // { x:100 }
console.log(a)
}
let say = fn.myBind({ x: 100 }, 1, 2, 3)(4);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
以下是对实现的分析:
- 前几步和之前的实现差不多,就不赘述了
- bind 返回了一个函数,对于函数来说有两种方式调用,一种是直接调用,一种是通过 new 的方式,我们先来说直接调用的方式
- 对于直接调用来说,这里选择了 apply 的方式实现,但是对于参数需要注意以下情况:因为 bind 可以实现类似这样的代码 f.bind(obj, 1)(2),所以我们需要将两边的参数拼接起来,于是就有了这样的实现 args.concat(...arguments)
其它简单实现方法:
Function.prototype._bind = function(...args) {
if (typeof this !== 'function') return;
// 获取this 数组args的第一项 (要指向的this { x: 100 })
const _this = args.shift();
// 获取fn._bind(....)中fn
const self = this;
return function() {
return self.apply(_this, args);
};
};
// 测试代码
function fn() {
console.log(this); // { x:100 }
}
let say = fn._bind({ x: 100 }, 1, 2, 3);
say();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
Function.prototype._bind = function() {
if (typeof this !== 'function') return;
// 利用Array原型对象上的slice()方法,该方法返回一个新的数组。获取传入的参数arguments
const args = Array.prototype.slice.call(arguments);
const _this = args.shift();
const self = this;
return function() {
return self.apply(_this, args);
};
};
// 测试代码
function fn() {
console.log(this);
}
let say = fn._bind({ x: 100 }, 1, 2, 3);
say(); // { x:100 }
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
Function.prototype._bind = function() {
if (typeof this !== 'function') return;
const args = Array.from(arguments);
const _this = args.shift();
const self = this;
return function() {
return self.apply(_this, args);
};
};
// 测试代码
function fn() {
console.log(this);
}
let say = fn._bind({ x: 100 }, 1, 2, 3);
say(); // { x:100 }
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# new
在调用 new 的过程中会发生以上四件事情:
- 新生成了一个对象
- 链接到原型
- 绑定 this
- 返回新对象
根据以上几个过程,我们也可以试着来自己实现一个 new:
function create() {
// 创建一个空对象
let obj = {}
// 获取构造函数
let Con = [].shift.call(arguments)
// 设置空对象的原型
obj.__proto__ = Con.prototype
// 绑定 this 并执行构造函数
let result = Con.apply(obj, arguments)
// 确保返回值为对象
return result instanceof Object ? result : obj
}
2
3
4
5
6
7
8
9
10
11
12
对于对象来说,其实都是通过 new 产生的,无论是 function Foo() 还是 let a = { b : 1 } 。
对于创建一个对象来说,更推荐使用字面量的方式创建对象(无论性能上还是可读性)。因为你使用 new Object() 的方式创建对象需要通过作用域链一层层找到 Object,但是你使用字面量的方式就没这个问题。
function Foo() {}
// function 就是个语法糖
// 内部等同于 new Function()
let a = { b: 1 }
// 这个字面量内部也是使用了 new Object()
2
3
4
5
# instanceof 的原理
instanceof 可以正确的判断对象的类型,因为内部机制是通过判断对象的原型链中是不是能找到类型的 prototype。
我们也可以试着实现一下 instanceof:
function myInstanceof(left, right) {
let prototype = right.prototype
left = left.__proto__
while (true) {
if (left === null || left === undefined)
return false
if (prototype === left)
return true
left = left.__proto__
}
}
2
3
4
5
6
7
8
9
10
11
以下是对实现的分析:
- 首先获取类型的原型
- 然后获得对象的原型
- 然后一直循环判断对象的原型是否等于类型的原型,直到对象原型为 null,因为原型链最终为 null
# 为什么 0.1 + 0.2 != 0.3
先说原因,因为 JS 采用 IEEE 754 双精度版本(64位),并且只要采用 IEEE 754 的语言都有该问题。
我们都知道计算机是通过二进制来存储东西的,那么 0.1 在二进制中会表示为:
// (0011) 表示循环
0.1 = 2^-4 * 1.10011(0011)
2
我们可以发现,0.1 在二进制中是无限循环的一些数字,其实不只是 0.1,其实很多十进制小数用二进制表示都是无限循环的。这样其实没什么问题,但是 JS 采用的浮点数标准却会裁剪掉我们的数字。
IEEE 754 双精度版本(64位)将 64 位分为了三段:
- 第一位用来表示符号
- 接下去的 11 位用来表示指数
- 其他的位数用来表示有效位,也就是用二进制表示 0.1 中的 10011(0011)
那么这些循环的数字被裁剪了,就会出现精度丢失的问题,也就造成了 0.1 不再是 0.1 了,而是变成了 0.100000000000000002
# V8 相关
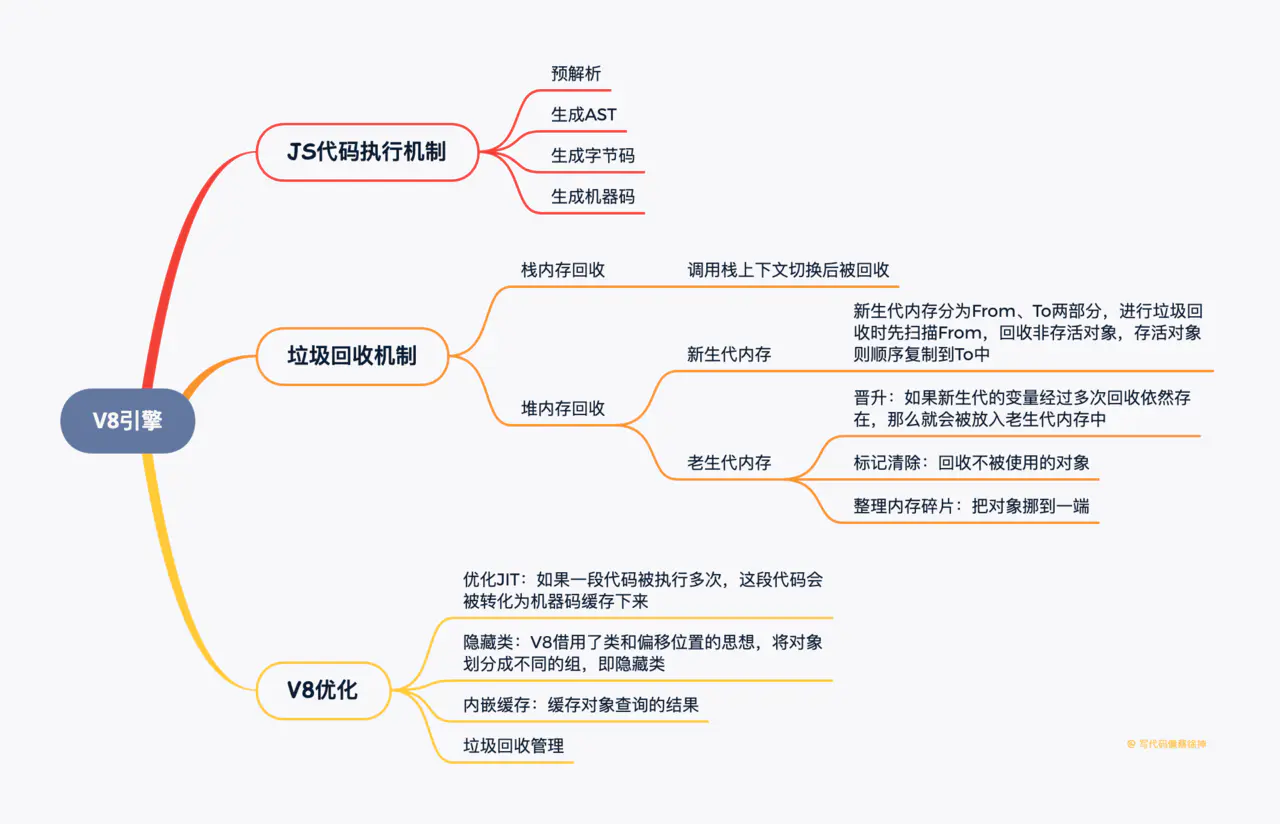
# V8如何执行一段JS代码
预解析:检查语法错误但不生成 AST
生成AST:经过词法/语法分析,生成抽象语法树
生成字节码:基线编译器(Ignition)将 AST 转换成字节码
由解释器逐行执行字节码,遇到热点代码启动编译器进行编译,生成对应的机器码, 以优化执行效率:优化编译器(Turbofan)将字节码转换成优化过的机器码,此外在逐行执行字节码的过程中,如果一段代码经常被执行,那么 V8 会将这段代码直接转换成机器码保存起来,下一次执行就不必经过字节码,优化了执行速度
以上是简单概述,详细请参考:
V8 是怎么跑起来的 —— V8 的 JavaScript 执行管道 (opens new window) JavaScript 引擎 V8 执行流程概述 (opens new window)
# JS相较于C++等语言为什么慢,V8做了哪些优化
JS的问题:
动态类型:导致每次存取属性/寻求方法时候,都需要先检查类型;此外动态类型也很难在编译阶段进行优化
属性存取:C++/Java等语言中方法、属性是存储在数组中的,仅需数组位移就可以获取,而JS存储在对象中,每次获取都要进行哈希查询
V8的优化:
优化JIT(即时编译):相较于C++/Java这类编译型语言,JS一边解释一边执行,效率低。V8对这个过程进行了优化:如果一段代码被执行多次,那么V8会把这段代码转化为机器码缓存下来,下次运行时直接使用机器码。
隐藏类:对于C++这类语言来说,仅需几个指令就能通过偏移量获取变量信息,而JS需要进行字符串匹配,效率低,V8借用了类和偏移位置的思想,将对象划分成不同的组,即隐藏类
内嵌缓存:即缓存对象查询的结果。常规查询过程是:获取隐藏类地址 -> 根据属性名查找偏移值 -> 计算该属性地址,内嵌缓存就是对这一过程结果的缓存
垃圾回收管理:下文马上介绍
详细请看为什么V8引擎这么快? (opens new window)
# 垃圾回收机制
V8 实现了准确式 GC,GC 算法采用了分代式垃圾回收机制。因此,V8 将内存(堆)分为新生代和老生代两部分。新生代就是临时分配的内存,存活时间短, 老生代是常驻内存,存活的时间长。V8 的堆内存,也就是两个内存 之和。
# 新生代算法
新生代中的对象一般存活时间较短,使用 Scavenge GC 算法。
首先是新生代的内存,刚刚已经介绍了调整新生代内存的方法,那它的内存默认限制是多少?在 64 位和 32 位系统下分别为 32MB 和 16MB。够小吧,不过也很好理解,新生代中的变量存活时间短,来了马上就走,不容易产生太大的内存负担,因此可以将它设的足够小。
在新生代空间中,内存空间分为两部分,分别为 From 空间和 To 空间。在这两个空间中,必定有一个空间是使用的,另一个空间是空闲的。新分配的对象会被放入 From 空间中,当 From 空间被占满时,新生代 GC 就会启动了。算法会检查 From 空间中存活的对象并复制到 To 空间中,如果有失活的对象就会销毁。当复制完成后将 From 空间和 To 空间互换,这样 GC 就结束了。
Scavenge GC 算法主要就是解决内存碎片的问题,不过 Scavenge GC 算法的劣势也非常明显,就是内存只能使用新生代内存的一半,但是它只存放生命周期短的对象,这种对象一般很少,因此时间性能非常优秀。
# 老生代算法
新生代中的变量如果经过多次回收后依然存在,那么就会被放入到老生代内存中,这种现象就叫晋升。
发生晋升其实不只是这一种原因,我们来梳理一下会有那些情况触发晋升:
- 新生代中的对象是否已经经历过一次 Scavenge 算法,如果经历过的话,会将对象从新生代空间移到老生代空间中。
- To 空间的对象占比大小超过 25 %。在这种情况下,为了不影响到内存分配,会将对象从新生代空间移到老生代空间中。
老生代中的对象一般存活时间较长且数量也多,使用了两个算法,分别是标记清除算法和标记压缩算法。
老生代中的空间很复杂,有如下几个空间
enum AllocationSpace {
// TODO(v8:7464): Actually map this space's memory as read-only.
RO_SPACE, // 不变的对象空间
NEW_SPACE, // 新生代用于 GC 复制算法的空间
OLD_SPACE, // 老生代常驻对象空间
CODE_SPACE, // 老生代代码对象空间
MAP_SPACE, // 老生代 map 对象
LO_SPACE, // 老生代大空间对象
NEW_LO_SPACE, // 新生代大空间对象
FIRST_SPACE = RO_SPACE,
LAST_SPACE = NEW_LO_SPACE,
FIRST_GROWABLE_PAGED_SPACE = OLD_SPACE,
LAST_GROWABLE_PAGED_SPACE = MAP_SPACE
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
在老生代中,以下情况会先启动标记清除算法:
- 某一个空间没有分块的时候
- 空间中被对象超过一定限制
- 空间不能保证新生代中的对象移动到老生代中
标记清除算法分为两步:
- 第一步,进行标记-清除:主要分成两个阶段,即标记阶段和清除阶段。
- 当函数被调用,变量进入上下文时,会被加上存在上下文标记,是不会被清理的。
- 当函数执行完成后,就会去掉存在上下文中的标记,随后垃圾回收程序会做一次内存清理,销毁这些变量。
function fn() {
var a = 1; // 函数调用时 被标记 进入上下文
}
test(); // 函数执行完毕,a的标记去掉,被回收
2
3
4
在标记大型对内存时,可能需要几百毫秒才能完成一次标记。这就会导致一些性能上的问题。
为了解决这个问题,2011 年,V8 从 stop-the-world 标记切换到增量标志。在增量标记期间,GC 将标记工作分解为更小的模块,可以让 JS 应用逻辑在模块间隙执行一会,从而不至于让应用出现停顿情况。但在 2018 年,GC 技术又有了一个重大突破,这项技术名为并发标记。该技术可以让 GC 扫描和标记对象时,同时允许 JS 运行。
- 第二步,整理内存碎片:清除对象后会造成堆内存出现碎片的情况,当碎片超过一定限制后会启动压缩算法。在压缩过程中,将活的对象像一端移动,直到所有对象都移动完成然后清理掉不需要的内存。
此外,还有引用计数算法: - 引用计数就是追踪值被引用的次数。声明变量并给它赋一个引用类型值时,这个值的引用数 为 1。 - 如果同一个值又被赋给另一个变量,那引用数+1 。如果保存该值引用的变量被其它值覆 盖了,则引用数减 1。 - 当引用计数为 0 时,表示这个值不再用到,垃圾收集器就会回收他所占用的内存。
<script>
var a = [1, 2, 3]; // [1,2,3]的引用计数为1
var b = a; // 变量b也引用了这个数组,所以[1,2,3]的引用数为2
var a = null; // [1,2,3]的引用被切断,引用数-1,所以[1,2,3]的引用数为1
// 如果只是到这里,那[1,2,3]不所占的内存不会被回收
var b = null; // [1,2,3] 的引用被切断,引用数-1,所 [1,2,3]的引用数为0
// 到这里,垃圾收集器在下一次清理内存时,就会把[1,2,3]所占的内存清理掉
</script>
2
3
4
5
6
7
8
引用计数有一个很大的坑,就是循环引用时,会造成内存永远无法释放。
# 总结概述
JS引擎中对变量的存储主要有两种位置,栈内存和堆内存,栈内存存储基本类型数据以及引用类型数据的内存地址,堆内存储存引用类型的数据
栈内存的回收:
栈内存调用栈上下文切换后就被回收,比较简单
堆内存的回收:
V8 的堆内存分为新生代内存和老生代内存,新生代内存是临时分配的内存,存在时间短,老生代内存存在时间长
新生代内存回收机制:
- 新生代内存容量小,64位系统下仅有32M。新生代内存分为From、To两部分,进行垃圾回收时,先扫描From,将非存活对象回收,将存活对象顺序复制到To中,之后调换From/To,等待下一次回收
老生代内存回收机制
- 晋升:如果新生代的变量经过多次回收依然存在,那么就会被放入- 老生代内存中
- 标记清除:老生代内存会先遍历所有对象并打上标记,然后对正在使用或被强引用的对象取消标记,回收被标记的对象
- 整理内存碎片:把对象挪到内存的一端
详细请看: 聊聊V8引擎的垃圾回收 (opens new window)
参考链接